可以用来定位 I/O 性能问题的工具有很多。常见的有 fio, dd, atop, iotop, iostat, vmstat 等。vmstat 可以提供系统性能的一个概览,一般可以看出来性能问题究竟是不是 I/O 的锅。想要具体查看每个设备的 I/O 情况,如 average request size, reads or writes per second,可以使用 iostat。
blktrace 介绍
更细粒度的分析,可以使用 blktrace。 blktrace 可以记录在 I/O 栈的多个阶段分别耗时多少。blktrace 的输出结果是二进制文件,可以用 blkparse 解析,但是它仍然很难读,需要使用 btt 来进一步转换成更易读的形式。
btt 输出结果涉及到的一些基础知识
btt 会对 I/O 栈 的不同阶段的耗时做分析,这些阶段是指:
Q — A block I/O is Queued
G — Get Request
M — A block I/O is Merged with an existing request.
I — A request is Inserted into the device's queue.
D — A request is issued to the Device.
C — A request is Completed by the driver.
从Q到C(简称Q2C),就是整个I/O从生成请求到I/O请求执行完毕所花费的时间。 从D到C,就是磁盘处理能力的指标,如果这个阶段时间长,说明磁盘性能可能出现问题。 从I到D,就是请求在 linux 的磁盘调度器中等待的时间,如果这各阶段时间长,说明操作系统的磁盘调度算法出了问题。 btt 会输出这些具有参考意义的阶段所耗费的时间,见下文示例。
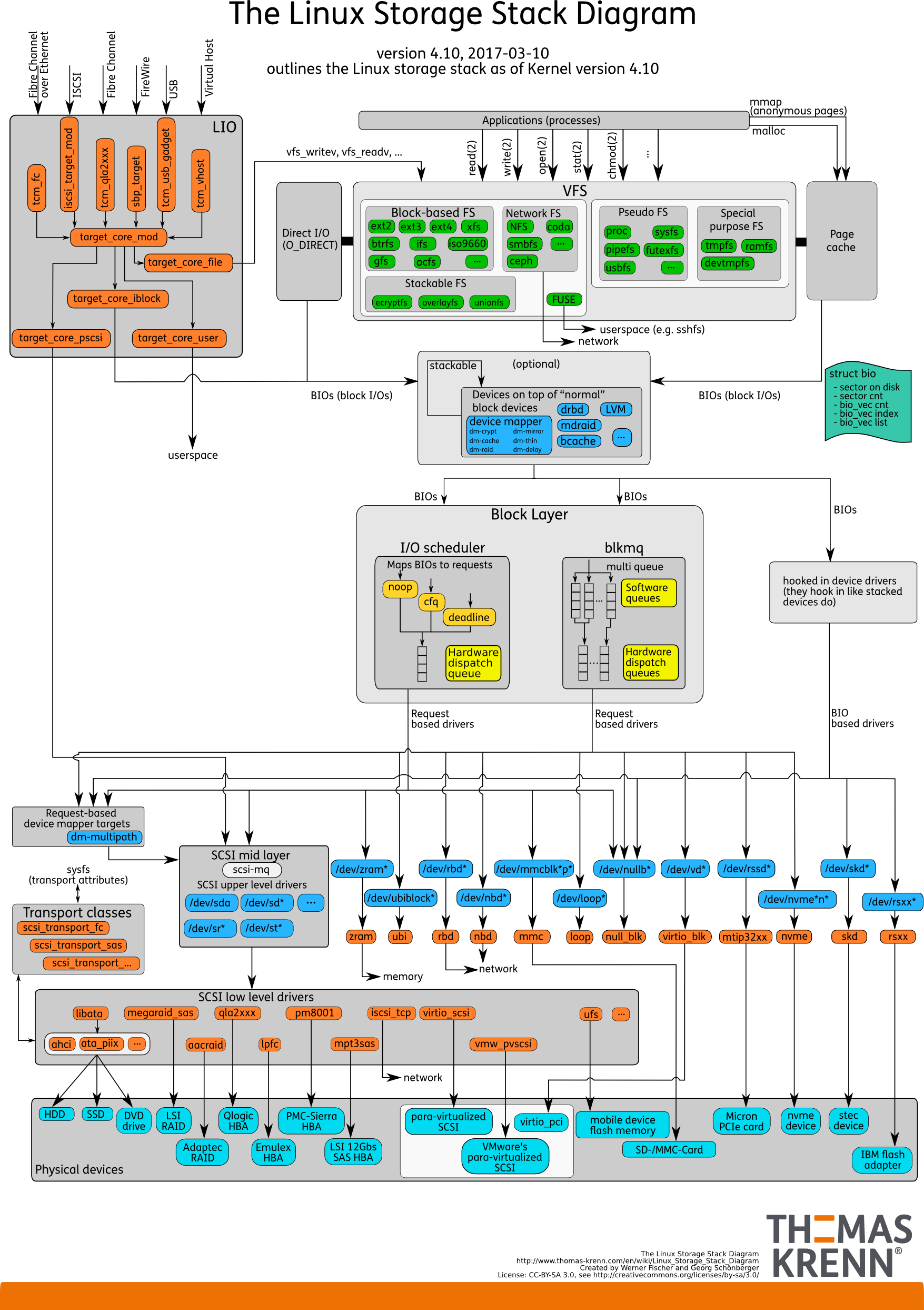
linux storage stack diagram
想要熟悉 linux 存储栈全貌的同学,可以看外网的这张图(linux kernel 4.10)
blktrace 定位问题一例
我们的应用通常会同时支持欧拉和 SUSE12SP5,在同样的硬件上,某数据库表现出了非常明显的性能差异,经过一段时间的定位,我们将方向集中在了底层 I/O 上,最终使用 blktrace 分析 I/O 各个阶段的耗时,发现了磁盘的调度(上文中的 I2D 阶段)存在问题。
- 使用的命令
1linux-x4ie:~ # mkdir temp # 下面的命令会生成很多文件,可以建一个临时文件夹
2linux-x4ie:~ # cd temp/
3linux-x4ie:~/temp # blktrace -d /dev/sda # 当你在压测的时候,执行这个命令,跑一段时间后随时可以ctrl-c结束掉。将sda换成你要观察的磁盘
4linux-x4ie:~/temp # blkparse -i sda -d sda.result # 生成一个 sda.result 文件
5linux-x4ie:~/temp # btt -i sda.result |less # 查看这个文件
- 输出的结果
1==================== All Devices ====================
2
3 ALL MIN AVG MAX N
4--------------- ------------- ------------- ------------- -----------
5
6Q2Q 0.000001149 0.050098409 2.542294316 105
7Q2G 0.000000384 0.000418363 0.017517435 42
8G2I 0.000001403 0.000044652 0.000121103 35
9Q2M 0.000000246 0.000000488 0.000002328 64
10I2D 0.000001076 0.000025743 0.000065505 37
11M2D 0.000001600 0.000038680 0.000143556 62
12D2C 0.000151619 0.009729193 0.024307440 106
13Q2C 0.000170782 0.009945783 0.033631640 106
14
15==================== Device Overhead ====================
16
17 DEV | Q2G G2I Q2M I2D D2C
18---------- | --------- --------- --------- --------- ---------
19 ( 8, 0) | 1.6667% 0.1482% 0.0030% 97.8223% 0.0903%
20---------- | --------- --------- --------- --------- ---------
21 Overall | 1.6667% 0.1482% 0.0030% 97.8223% 0.0903%
22
23==================== Device Merge Information ====================
24
25 DEV | #Q #D Ratio | BLKmin BLKavg BLKmax Total
26---------- | -------- -------- ------- | -------- -------- -------- --------
27 ( 8, 0) | 106 42 2.5 | 8 20 176 856
28
29==================== Device Q2Q Seek Information ====================
30
31 DEV | NSEEKS MEAN MEDIAN | MODE
32---------- | --------------- --------------- --------------- | ---------------
33 ( 8, 0) | 106 17264326.0 0 | 0(69)
34---------- | --------------- --------------- --------------- | ---------------
35 Overall | NSEEKS MEAN MEDIAN | MODE
36 Average | 106 17264326.0 0 | 0(69)
btt 的报告,我们可以看 Device Overhead (设备开销)部分。这份报告中,很明显耗时都在 I2D 阶段(97.8223%),定位方向就可以去往操作系统的调度器调整了。
在 /sys/block/sda/queue/scheduler (不同 linux 发行版的位置可能不同)中,可以看到 sda 磁盘当前的调度器。如
1cat /sys/block/sda/queue/scheduler
2noop deadline [cfq] #中括号中代表当前生效的算法
3echo deadline > /sys/block/sda/queue/scheduler #直接echo更改,无需重启服务和机器。重启机器失效
4noop [deadline] cfq
I/O scheduler
从上文 Thomas Krenn 的 linux storage stack diagram 图中,也能看出在 I/O scheduler 有 noop, cfq, deadline. 不同的操作系统,内核版本,支持的调度器都不同。
调度器
在我司实际工作过程中,以下几种调度器都遇到过:
| 单队列调度器 | 简介 |
|---|---|
| deadline | 每个读写请求都有生命时间,时间到了就先处理。读是500ms,写是5s。解决了下面两个算法的饿死问题 |
| cfq | Completely Fair Queueing,完全公平队列,可能造成时间浪费 |
| noop | 合并IO请求但是不做排序,随机写入好的盘如闪存盘,现在比较火的nvme等,或者一些自己会去排序的高级存储控制器比较适合这个算法 |
多队列调度器(欧拉镜像,suse等虚拟机镜像)
| 多队列调度器 | 简介 |
|---|---|
| none | noop算法的多队列版本 |
| kyber | 简单的算法,一个同步队列,一个异步队列,每个队列都有请求数量的限制 |
| mq-deadline | 类似deadline,不过考虑了多队列 |
| bfq | 适合CPU较好但是IO较差的场景,CPU不好的时候不要用 |
由此可见,调度器的选择要视硬件、应用、场景综合判断,错误的选择可能造成数倍的性能差异(在我们的场景下,测试同学反馈的是性能相差近一百倍)。 另外,我在 Oracle 的官网上还发现了这样一句话,供参考:
For best performance for Oracle ASM, Oracle recommends that you use the Deadline I/O Scheduler.