可以用來定位 I/O 性能問題的工具有很多。常見的有 fio, dd, atop, iotop, iostat, vmstat 等。vmstat 可以提供系統性能的一個概覽,一般可以看出來性能問題究竟是不是 I/O 的鍋。想要具體查看每個設備的 I/O 情況,如 average request size, reads or writes per second,可以使用 iostat。
blktrace 介紹
更細粒度的分析,可以使用 blktrace。 blktrace 可以記錄在 I/O 棧的多個階段分別耗時多少。blktrace 的輸出結果是二進制文件,可以用 blkparse 解析,但是它仍然很難讀,需要使用 btt 來進一步轉換成更易讀的形式。
btt 輸出結果涉及到的一些基礎知識
btt 會對 I/O 棧 的不同階段的耗時做分析,這些階段是指:
Q — A block I/O is Queued
G — Get Request
M — A block I/O is Merged with an existing request.
I — A request is Inserted into the device's queue.
D — A request is issued to the Device.
C — A request is Completed by the driver.
從Q到C(簡稱Q2C),就是整個I/O從生成請求到I/O請求執行完畢所花費的時間。 從D到C,就是磁盤處理能力的指標,如果這個階段時間長,說明磁盤性能可能出現問題。 從I到D,就是請求在 linux 的磁盤調度器中等待的時間,如果這各階段時間長,說明操作系統的磁盤調度算法出了問題。 btt 會輸出這些具有參考意義的階段所耗費的時間,見下文示例。
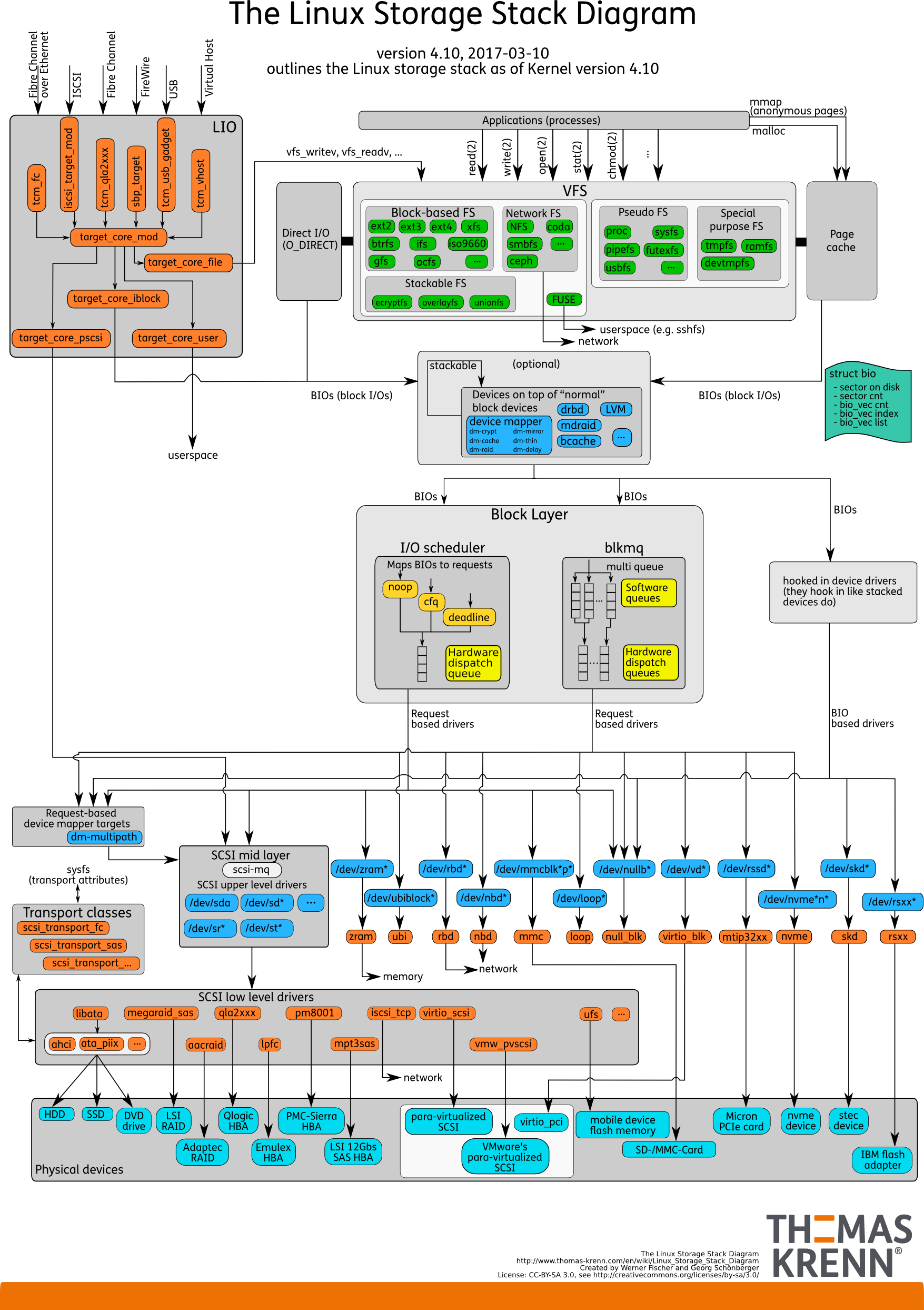
linux storage stack diagram
想要熟悉 linux 存儲棧全貌的同學,可以看外網的這張圖(linux kernel 4.10)
blktrace 定位問題一例
我們的應用通常會同時支持歐拉和 SUSE12SP5,在同樣的硬件上,某數據庫表現出了非常明顯的性能差異,經過一段時間的定位,我們將方向集中在了底層 I/O 上,最終使用 blktrace 分析 I/O 各個階段的耗時,發現了磁盤的調度(上文中的 I2D 階段)存在問題。
- 使用的命令
1linux-x4ie:~ # mkdir temp # 下面的命令會生成很多文件,可以建一個臨時文件夾
2linux-x4ie:~ # cd temp/
3linux-x4ie:~/temp # blktrace -d /dev/sda # 當你在壓測的時候,執行這個命令,跑一段時間後隨時可以ctrl-c結束掉。將sda換成你要觀察的磁盤
4linux-x4ie:~/temp # blkparse -i sda -d sda.result # 生成一個 sda.result 文件
5linux-x4ie:~/temp # btt -i sda.result |less # 查看這個文件
- 輸出的結果
1==================== All Devices ====================
2
3 ALL MIN AVG MAX N
4--------------- ------------- ------------- ------------- -----------
5
6Q2Q 0.000001149 0.050098409 2.542294316 105
7Q2G 0.000000384 0.000418363 0.017517435 42
8G2I 0.000001403 0.000044652 0.000121103 35
9Q2M 0.000000246 0.000000488 0.000002328 64
10I2D 0.000001076 0.000025743 0.000065505 37
11M2D 0.000001600 0.000038680 0.000143556 62
12D2C 0.000151619 0.009729193 0.024307440 106
13Q2C 0.000170782 0.009945783 0.033631640 106
14
15==================== Device Overhead ====================
16
17 DEV | Q2G G2I Q2M I2D D2C
18---------- | --------- --------- --------- --------- ---------
19 ( 8, 0) | 1.6667% 0.1482% 0.0030% 97.8223% 0.0903%
20---------- | --------- --------- --------- --------- ---------
21 Overall | 1.6667% 0.1482% 0.0030% 97.8223% 0.0903%
22
23==================== Device Merge Information ====================
24
25 DEV | #Q #D Ratio | BLKmin BLKavg BLKmax Total
26---------- | -------- -------- ------- | -------- -------- -------- --------
27 ( 8, 0) | 106 42 2.5 | 8 20 176 856
28
29==================== Device Q2Q Seek Information ====================
30
31 DEV | NSEEKS MEAN MEDIAN | MODE
32---------- | --------------- --------------- --------------- | ---------------
33 ( 8, 0) | 106 17264326.0 0 | 0(69)
34---------- | --------------- --------------- --------------- | ---------------
35 Overall | NSEEKS MEAN MEDIAN | MODE
36 Average | 106 17264326.0 0 | 0(69)
btt 的報告,我們可以看 Device Overhead (設備開銷)部分。這份報告中,很明顯耗時都在 I2D 階段(97.8223%),定位方向就可以去往操作系統的調度器調整了。
在 /sys/block/sda/queue/scheduler (不同 linux 發行版的位置可能不同)中,可以看到 sda 磁盤當前的調度器。如
1cat /sys/block/sda/queue/scheduler
2noop deadline [cfq] #中括號中代表當前生效的算法
3echo deadline > /sys/block/sda/queue/scheduler #直接echo更改,無需重啓服務和機器。重啓機器失效
4noop [deadline] cfq
I/O scheduler
從上文 Thomas Krenn 的 linux storage stack diagram 圖中,也能看出在 I/O scheduler 有 noop, cfq, deadline. 不同的操作系統,內核版本,支持的調度器都不同。
調度器
在我司實際工作過程中,以下幾種調度器都遇到過:
| 單隊列調度器 | 簡介 |
|---|---|
| deadline | 每個讀寫請求都有生命時間,時間到了就先處理。讀是500ms,寫是5s。解決了下面兩個算法的餓死問題 |
| cfq | Completely Fair Queueing,完全公平隊列,可能造成時間浪費 |
| noop | 合併IO請求但是不做排序,隨機寫入好的盤如閃存盤,現在比較火的nvme等,或者一些自己會去排序的高級存儲控制器比較適合這個算法 |
多隊列調度器(歐拉鏡像,suse等虛擬機鏡像)
| 多隊列調度器 | 簡介 |
|---|---|
| none | noop算法的多隊列版本 |
| kyber | 簡單的算法,一個同步隊列,一個異步隊列,每個隊列都有請求數量的限制 |
| mq-deadline | 類似deadline,不過考慮了多隊列 |
| bfq | 適合CPU較好但是IO較差的場景,CPU不好的時候不要用 |
由此可見,調度器的選擇要視硬件、應用、場景綜合判斷,錯誤的選擇可能造成數倍的性能差異(在我們的場景下,測試同學反饋的是性能相差近一百倍)。 另外,我在 Oracle 的官網上還發現了這樣一句話,供參考:
For best performance for Oracle ASM, Oracle recommends that you use the Deadline I/O Scheduler.